AWS Step Functions and You
An overview of AWS Step Functions and when they might come in handy




What are AWS Step Functions?
Step functions are the project manager of the AWS Serverless environment.
They let you quickly create new state machines to manage workflows using various AWS services - from Lambda and DynamoDB to SNS - in a JSON-based language. These workflows come with the major benefit of a dynamically generated flowchart that is generated as you go along.
You have access to choice states, parallel execution of tasks and error catching, letting you create complex flows which are easy to track and explain even to non-technical colleagues and clients. Step Functions also take care of passing input and output between various states, letting you focus purely on the functional aspect of your code.

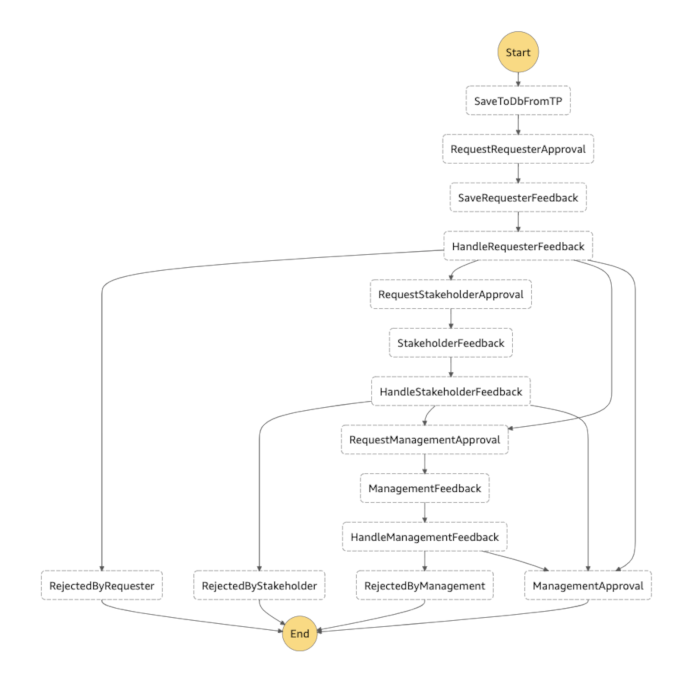
As you can see they can end up looking quite complicated - even when they define something quite simple like 3-step approval process.
We'll go through the basics now and by the end of this post you should feel comfortable that you have an understanding to build on.
When to use Step Functions?


In my personal experience there are four main benefits to Step Functions over orchestrating interactions between services yourself (whether in a Lambda or other use cases).
-
Observability - Tracking errors and their source can always be a bit of a pain in a microservice architecture. You won't necessarily have a unified event log as one process might have a large amount of Lambdas involved and the error might happen in any one of them. Step Functions show the current state of each execution, as well as a clear indication of which stage failed and the provided error message.
-
Simplicity - This ties in with observability in some ways. Looking at a Step Function definition even a very complex workflow becomes easily understandable. It helps both in getting a clear understanding of your project and possible improvements and in explaining it to stakeholders with less direct involvement in the code.
Another benefit is that it is very easy to implement comprehensive error handling and retrying.
-
Longevity - One of Step Functions' big draws is that they can run for a long time. A single execution can run for up to 1 year for an action to be completed, which makes things like waiting for user feedback (e.g. to a signup verification email), a breeze.
-
Reusability - Obviously a Step Function definition is only reusable to a limited degree, however the patterns you create can often be useful in many cases and for many customers. I will write about reusability more extensively in a future post.
Looking at these advantages it would seem like you should write every workflow as a Step Function from now on. While that sounds attractive, I don't think we are quite there yet.
My personal recommendation would be to reserve Step Functions for situations in which you have a very complex workflow (or a necessity to work closely with non-technical stakeholders), business critical operations in which you want as much visibility and control as possible, long running tasks which exceed Lambda runtimes and client agnostic flows which you might want to reuse again and again in different environments.
How do they work?


As I've said above, Step Functions let you define workflows. You create a number of possible states for your task to be in, as well as possible transitions from one state to another. You can pass input and output between states and assign error handling for the whole machine as well as individual steps.
Once a workflow has been defined you are presented with a visual representation and are able to track each execution through all states, seeing in clear terms where you are.
States
So, what are the building blocks we can use to build our state machine?
I will list all 7 possible states with a quick overview, however the best way to gain an understanding is to actually build something with them (which we will cover in following posts).
-
Task - The task state is where you orchestrate actual work in your state machine. You can invoke Lambda functions, various other AWS Services (including directly interacting with DynamoDB) and call custom activities (which I will give more detail on below).
-
Pass - The pass state simply passes any given input to output. It can also add predefined values to the output and is mostly used in debugging.
-
Wait - The wait state lets you wait for a specified amount of seconds, or until a specific date/timestamp. This value can be predefined or passed in as input.
-
Choice - The choice state is where things start to get interesting - it lets you create complex workflows responding to user choice. You specify an input field (or several) and a set of rules do decide which state to transition to.
-
Parallel - As the name suggests, this state allows for parallel execution of multiple other states. All of them must be defined and the machine will only progress to the next step once all of them are complete.
-
Fail - Indicates a failed execution.
-
Succeed - Indicates a successful execution.
Activities
Activities are where Step Functions really step up the game. Tasks let you invoke a certain subset of AWS Services, but Activities let you run code running pretty much anywhere.
This really extends your ability to orchestrate work to pretty much anything you can write.
Data (input and output)
All data passed is passed between states as JSON.
Input to a function is bound to the $ symbol and accessed from there. When a function returns a value, that is passed to the next state, dropping any previous input.
That is the default behaviour, but luckily we have access to some configuration.
You can specify a specific path on the input that you want to access (dropping all else) using the InputPath key. For example if your input is
{
'a': 100,
'b': 50
}
by default your function would have access to both, but by defining an Input path as InputPath: "$.a", the function would consider the input as
100
You can also define a ResultPath key, which will let you assign a functions output to a specific key on the $ object instead of overwriting it completely.
When things go wrong...
As I mentioned above, one of the areas where Step Functions can really shine is error handling.
You can define a retry definition for each step, which defines how and when to retry after a failed execution. It let's you define specific behaviour for specific errors, a maximum number of retries as well as a backoff strategy.
For cases where simply doing the same thing again isn't going to work, you can also define a catch field. Similarly to a try/catch block in normal code, the step is treated as the try section and you define which state to move to for each error state in case it errors.
In addition to state-specific catch blocks, you can also define global catches in case you want to move to a clean-up state no matter where your execution failed.
Combined with the visualisation in the Step Functions Console which displays whether an execution succeeded or failed, and if it did in which state, this should give you a good degree of confidence about building robust state machines.
First Steps
And there you have it, a quick overview of Step Functions.
There is a lot of depth in what you can build from these simple building blocks, but hopefully you have a rough idea of how they fit together now. As with most things, the best way to really internalise all this theory is by getting some practice and building a basic Step Function.
If you are interested in something somewhat more in depth, I will be writing more posts about Step Function and how to utilise them.
The second part in this series will focus on how specifically you can use Step Functions to reuse code and move faster in your development cycles and will contain a lot more hands-on content.
Ready to dive in?
At JDLT, we manage IT systems & build custom software for organisations of all sizes.
Get in touch to see how we can help your organisation.
Book a call